Overview
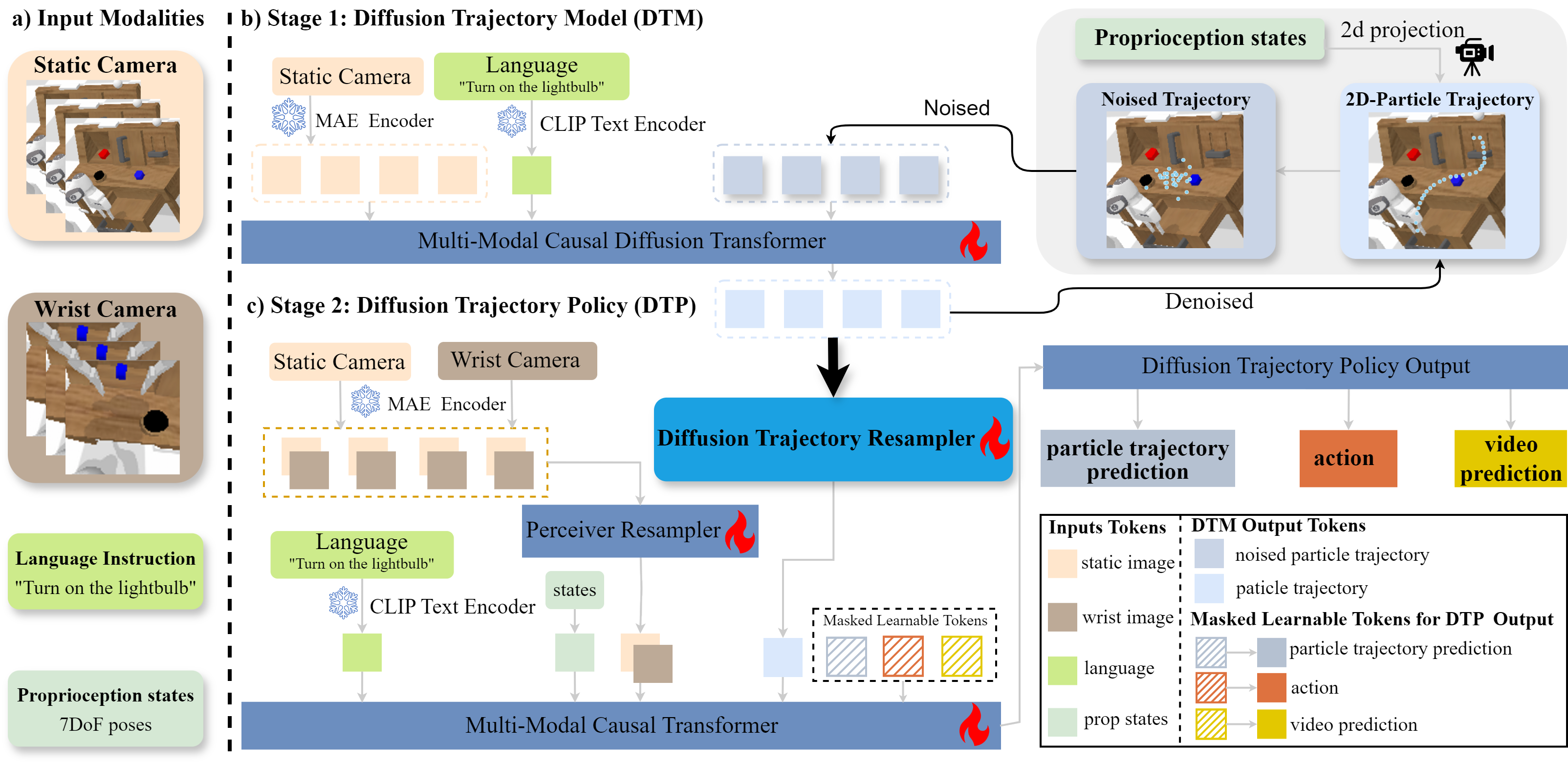
System overview. (a) and (b) present a task instruction with the initial task observation, allowing our Diffusion Trajectory Model to predict the complete future 2D-particle trajectories; (c) illustrates the Diffusion Trajectory-guided pipeline, showcasing how these predicted trajectories guide the manipulation policy.
Abstract
Recently, Vision-Language-Action models (VLA) have advanced robot imitation learning, but high data collection costs and limited demonstrations hinder generalization and current imitation learning methods struggle in out-of-distribution scenarios, especially for long-horizon tasks. A key challenge is how to mitigate compounding errors in imitation learning, which lead to cascading failures over extended trajectories. To address these challenges, we propose the Diffusion Trajectory-guided Policy (DTP) framework, which generates 2D trajectories through a diffusion model to guide policy learning for long-horizon tasks. By leveraging task-relevant trajectories, DTP provides trajectory-level guidance to reduce error accumulation. Our two-stage approach first trains a generative vision-language model to create diffusion-based trajectories, then refines the imitation policy using them. Experiments on the CALVIN benchmark show that DTP outperforms state-of-the-art baselines by 25% in success rate, starting from scratch without external pretraining. Moreover, DTP significantly improves real-world robot performance.
Experiments Setup
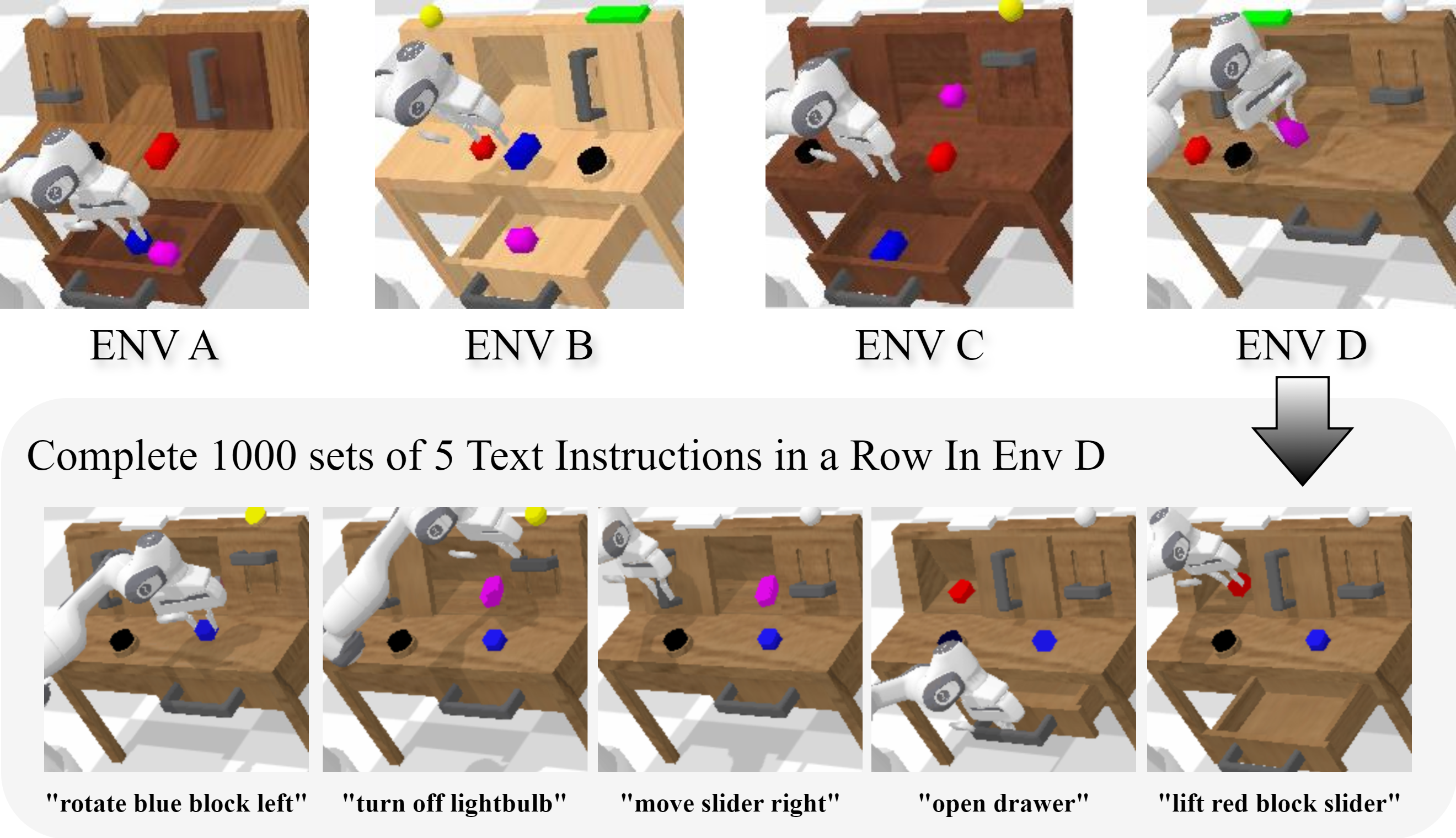
Here are some examples of the hardware setup for data collection, which is also the hardware setup we used to establish our real-world experiments. For the Franka Emika Panda robots, we use cameras positioned at the top, left, and right viewpoints to record the visual information of the task trajectories. For the AgileX/Tien Kung robots, we use their built-in cameras to record visual information. For UR robots, we use an external top camera. All demonstrations are collected using high-quality human teleoperation and stored on a unified intelligence platform.
Real-world Long-horizon Experiments
Our method's performance on a long sequence (divided into 5 subsequences), where the small window on the left side of the video displays the diffusion trajectory view, representing the Stage 1 DTM (Diffusion Trajectory Model) process, with the entire procedure orchestrated by the Stage 2 DTP (Diffusion Trajectory-guided Policy).
Video Presentation
BibTeX
@article{fan2025diffusion,
title={Diffusion trajectory-guided policy for long-horizon robot manipulation},
author={Fan, Shichao and Yang, Quantao and Liu, Yajie and Wu, Kun and Che, Zhengping and Liu, Qingjie and Wan, Min},
journal={IEEE Robotics and Automation Letters(RAL)},
year={2025}
}